
I am sure you must be wondering what the heck is Robots.txt and why I need it? Don’t worry about that right now. By the end of this article, you will know everything about Robots.txt and will also be able to add it to your WordPress website in seconds. In this article, I will cover each & every little information about Robots.txt file, so you don’t need to roam around places on the web for this information anymore. If I left you with any question then please leave me a message in the comment section below so I can make necessary updates to this article or write another one.
Before writing this article, I did research on what are the common questions people are asking in Google Webmaster Forum/Quora/Twitter on Robots.txt, Google Indexing, bot crawlings etc. Here are some of them which you might have right now in your mind –
- What is Robots.txt?
- What Robots.txt contains?
- What code should be written in Robots.txt File?
- Why is Google de-indexing already indexed URLs?
- Why google is indexing some of my private folders?
Don’t worry if you have some other questions in mind because in this article I will explain everything from scratch. For quick reference – Below is the table of content:
Table Of Content
- What is Robot.txt File?
- Why do you need Robot.txt file?
- How to access Robot.txt file from your c-panel?
- Explanation of Robots.txt file syntax.
- How to optimize WordPress Robots.txt file?
- How to Add XML Sitemap to Robots.txt file?
- What is an ideal Robots.txt file for a website?
- Are there any tools to generate and validate a Robots.txt file?
- Other Robots.txt resources.
What is Robot.txt File?
Robots.txt is a text file that you put on your website root directory (eg. www.domain.com/robots.txt). This text file is always named “robots.txt” and it follows a strict syntax. It’s also very important that your robots.txt file is really called “robots.txt” as this name is case sensitive. Make sure you name the file correctly or it will just now work for you.
Functionally, this file is the opposite of your sitemap. A site map exists to tell search engines what pages you want them to index and, a robots file does the opposite – it tells them what pages you don’t want them to index.
In this file, you specify which parts of your website should be crawled by spiders or web crawlers. You can specify different rules for different spiders/bots in Robots.txt file. Remember that it is by no means compulsory for search engines but generally, search engines obey what they are asked not to do.
Googlebot is an example of a spider. It’s deployed by Google to crawl the Internet and record information about websites so it knows how high to rank different websites in search results.
Why do you need Robot.txt file?
To explain you why do you need Robots.txt on your website, I will start from basics. First of all, you may be wondering – what are bots? Bots are search engine Robots or Spiders. They are designed to crawl a website and all the search engines have their own bots to do this activity. There are two key terms here that you should understand i.e. Crawling and Indexing. These are two different terms. On a high level, Crawling is following a path (links). For a website, crawling means following the web links. Indexing means adding those web links to the search engine. Indexing also depends on the meta tag which you use for your web pages (Meta tags – Index or noIndex).
Now, when a search engine bot (Google bot, Bing bot, or any search engine crawlers) comes to your site following a link or following your sitemap link that you have submitted to the webmaster search console, they follow all the links on your website to crawl and index your site.
How Bots/Crawlers Work –
When a search engine bots come on your website, they have limited resources to crawl your site. If they can’t crawl all the web pages on your website in given resources, they stop crawling, and this can hamper website indexing. It’s great if search engine completes indexing but there are many parts of the website which you want to protect from crawlers or bots. For example, the wp-admin folder, the admin dashboard or other pages, which are not useful for search engines. Using robots.txt, you can direct search engine crawlers (bots), to not to crawl such area of your website. This way you will not only speed up crawling of your website but will also help you in deep crawling of your inner pages.
Do remember that Robots.txt file is not for Index or Noindex but it’s just to direct search engine bots to stop crawling certain part of your blog. For example, if you look at the DigitalHarpreet robots.txt file, you will definitely understand, what part of my blog I don’t want search engine bots to crawl.
How to Access Robot.txt file?
Robot.txt file is located in the root directory of your website. In order to edit or view it, go to you c-panel and locate your file manager and then go to the public_html folder or you can connect your website to an FTP client to access it.
It is just like any normal text file, and you can open it with a plain text editor like Notepad. If you do not have a robots.txt file in your site’s root directory, then you can always create one. All you need to do is create a new text file on your computer and save it as robots.txt. Next, simply upload it to your site’s root folder.
Robots.txt file syntax
Here is an Example Robots.txt File.
User-agent: * Disallow: /ebooks/*.pdf Disallow: /staging/User-agent: Googlebot-Image Disallow: /images/
Where,
User-agent: * → The first line is defining the rules which should be followed by all web crawlers. Here asterisk means all spiders in this context.
Disallow: /ebooks/*.pdf → In connection with the first line, this link means that all web crawlers should not crawl any pdf files in the ebooks folder within this website. This means search engines won’t include these direct PDF links in search results.
Disallow: /staging/ → In connection with the first line, this line asks all crawlers not to crawl anything in the staging folder of the website. This can be helpful if you’re running a test and don’t want the staged content to appear in search results.
User-agent: Googlebot-Image — This explains that the rules that follow should only be followed by just one specific crawler i.e. the Google Image crawler. Each spider uses a different “user-agent” name.
Disallow: /images/ — In connection with the line immediately above this one, this asks the Google Images crawler not to crawl any images in the images folder.
How to optimize WordPress robots.txt file SEO?
Robots.txt file helps you to safeguard your things from web crawlers/bots if coded correctly but if you configure it incorrectly then it could harm your web presence go away completely. So, it is highly recommended to follow extra caution when you make changes in this file.
At this point, I am assuming that you are reading this article from the top and you already know how to access you robots.txt file. If you don’t have robots.txt on your site then you can create a new one using Notepad (.txt file). While you create that file, make sure you name it correctly i.e. robots.txt and then FTP that file to the root of your website. If you are not using FTP client then go your c-panel and locate File manager and then upload your file to the root directory (public_html).
Once you have located your Robots.txt file, its time to write something to it. Now before you write into this file, the question is –What you want your Robots.txt file to do for you?
There are three ways you can code your Robots.txt file –
- Code it to Allow Everything – All content can be crawled by the bots.
- Code it to Disallow Everything – No content can be crawled by the bots.
- Code it to Conditional Allow few things– Directions written in the robots.txt file will determine what content to crawl and what not.
Let’s see how to code above three options in Robots.txt –
Allow Everything – All content can be crawled by the bots –
Most people want robots to visit everything on their website. If this is the case with you, and you want the robot to index all parts of your site then there are three ways to achieve this –
- Do not have a Robots.txt at all on the website.
- Make an empty Robots.txt file and add it to the root of your website.
- Make a robots.txt file and write the following code in it.
User-agent: *
Disallow:
If your website has a robots.txt with these instructions in it then this is what happens. A robot e.g. Googlebot comes to visit. It looks for the robots.txt file. It finds the file and reads it. It reads the first line. Then it reads the second line. The robot then feels free to visit all your web pages and content because this is what you told it to do.
Disallow Everything – No content can be crawled by the bots –
Warning – By doing this, you mean that Google and other search engines will not index your web pages.
To block all the search engine crawlers from your website, you need to add following lines to your robots.txt file –
User-agent: * Disallow: /
Conditional Allow – Directions written in the robots.txt file will determine what content to crawl and what not.
Here is the sample robot.txt file for WordPress with conditional allow/disallow statements.
User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /archives/ disallow: /*?* Disallow: *?replytocom Disallow: /comments/feed/ User-agent: Mediapartners-Google* Allow: / User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: Adsbot-Google Allow: / User-agent: Googlebot-Mobile Allow: / Sitemap: https://www.yourdomain.com/sitemap.xml
***Important Robots.txt coding guidelines –
- Don’t use comments in Robots.txt file.
- Make sure you don’t add any spaces in the beginning of your directives. For example,
User-agent: * is WRONG way of writing in robots.txt User-agent: * is the CORRECT way of writing in robots.txt
- Don’t change the order of commands. For example,
Disallow: /support
User-agent: * This is incorrect directives.
Instead of writing these commands, you should write them as shown below:
User-agent: *
Disallow: /support
- If you want to disallow multiple directories then write below lines in robots.txt,
User-agent: *
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /archives/
Instead of writing then all together like this –
User-agent: *
Disallow: /cgi-bin /wp-admin /archives
- Use capital and small letters carefully. For example, if you want to disallow “readme.html” but if you write it as “Readme.html” then it will confuse search engine bot and eventually you will get the desired result.
- Avoid logical errors. For example –
User-agent: *
Disallow: /temp/
User-agent: Googlebot
Disallow: /images/
Disallow: /temp/
Disallow: /cgi-bin/
The above example is from a robots.txt that allows all agents to access everything on the site except the /temp directory. Up to here, it is fine but later on, there is another record that specifies more restrictive terms for Googlebot. When Googlebot starts reading robots.txt, it will see that all user agents (including Googlebot itself) are allowed to all folders except /temp/. This is enough for Googlebot to know, so it will not read the file to the end and will index everything except /temp/ – including /images/ and /cgi-bin/, which you think you have told it not to touch. You see, the structure of a robots.txt file is simple but still serious mistakes can be made easily.
How to Add XML Sitemap to Robots.txt file?
You can achieve this adding below lines to robots.txt. You can replace the below sitemap links with your own website sitemap.xml.
If you want to generate XML sitemap for FREE – Read this:
- FREE XML Sitemap Generator – Google Recommended
- Learn What is XML Sitemap & How do I generate one for my website.
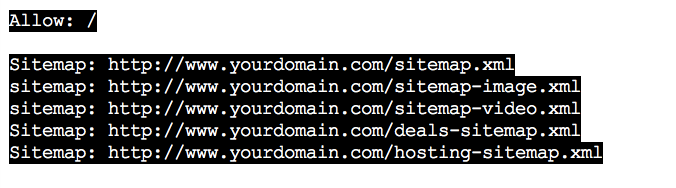
What is an ideal Robots.txt file for my website?
If you want an ideal Robots.txt file, then this is what it should be –

Here is another example of robots.txt that I user at https://digitalharpreet.com/robots.txt
User-agent: * Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-content/plugins/ Disallow: /readme.html Disallow: /index.php Disallow: /xmlrpc.php User-agent: NinjaBot Allow: / User-agent: Mediapartners-Google* Allow: / User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: Adsbot-Google Allow: / User-agent: Googlebot-Mobile Allow: / sitemap: https://digitalharpreet.com/sitemap_index.xml sitemap: https://digitalharpreet.com/post-sitemap.xml sitemap: https://digitalharpreet.com/page-sitemap.xml sitemap: https://digitalharpreet.com/category-sitemap.xml
Tools to Generate and Validate a Robots.txt File
You can directly generate robot.txt in Optimal WordPress Robots Generator. Generate you robot.txt and add it in root Directory.
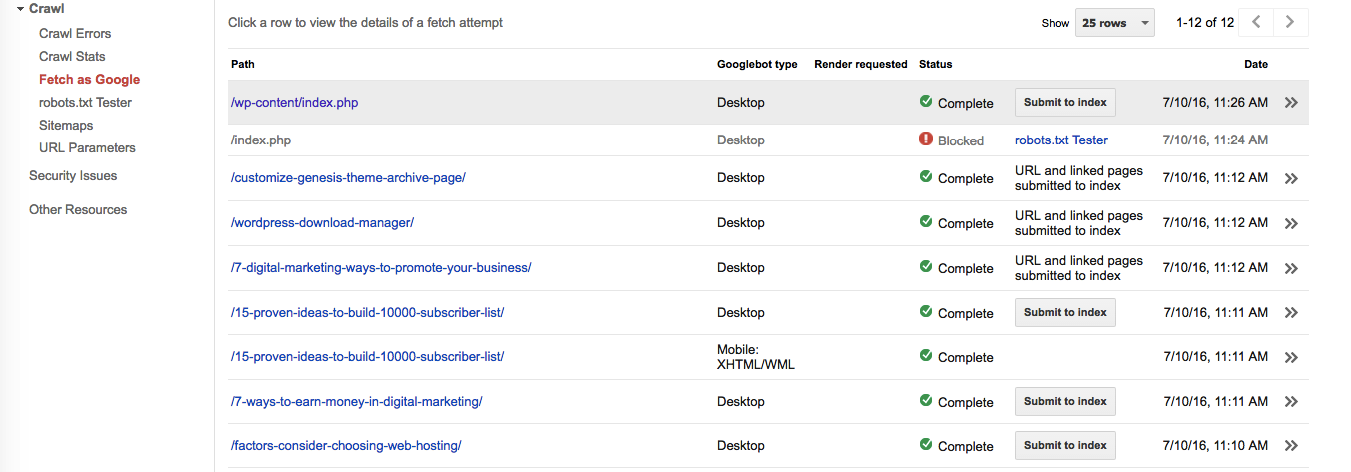
To validate Robots.txt file,
- Login to Google Webmaster tool dashboard.
- Click on “Crawl” and then “Fetch as Google”.
- Add your site posts and check if there is any issue accessing your post.
- Also, add posts/pages that you have disallowed in the robots.txt file.
This is how it will look –
Other Robots.txt Resources
Let me know if you still in doubt or have any question in mind? You can post your question below or you can tweet me here using below link to start a conversation –
[Tweet “@hpsiddhu, I need more clarification with regard to your article on Robots.txt. “]
Or you can send me an email at support@digitalharpreet.com.
And if you are already using robots.txt for your WordPress website and would like to add more useful information to this article then you are more than welcome to leave your valuable comment to help other readers.
Don’t forget to subscribe to blog to keep receiving useful SEO related tips.
[mailmunch-form id=”356871″]
You might like to read this too – Check it out
How To Block link Cralwers like Majestic Ahrefs Moz and SEMRush



The primary question which generally bothers website owners is that how easy it is for search engines to crawl websites? Since Internet is vast and new contents are being regularly updated, it becomes virtually impossible for search engine robots to crawl the entire content present online. This means that only a percentage of this content is crawled by search engine spiders. Moreover amongst the crawled content, only a portion is indexed due to availability of limited resources.
Wow! In the end I got a weblog from where I be able to actually take
useful information concerning my study and knowledge.